データを統計学ではどの様に見て行くのかをまとめます。
また今回は実際にデータを可視化していきます。サンプルで使うデータとしてirisデータセットを使用します。
環境はcolaboratoryで行い、python、scikit-learn、pandasなどを用います。
データの準備
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
pd.DataFrame(iris.data, columns=iris.feature_names)
実行すると以下の様なデータが取得できます。
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
| 5 | 5.4 | 3.9 | 1.7 | 0.4 |
| … | … | … | … | … |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 |
このデータはあやめの花のデータでそれぞれの変数は以下の様な意味です。
| feature_name | 意味 |
|---|---|
| sepal length (cm) | がく片の長さ |
| sepal width (cm) | がく片の幅 |
| petal length (cm) | 花弁の長さ |
| petal width (cm) | 花弁の幅 |
今回はこのデータを使って見ていきます。
データについて
まず、pandasで簡単にデータの詳細を確認できるので以下のコマンドで見ておきます。
df.describe()
実行結果はこんな感じ。
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.054000 | 3.758667 | 1.198667 |
| std | 0.828066 | 0.433594 | 1.764420 | 0.763161 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
度数分布表とヒストグラム
度数分布表とヒストグラムは、取得したデータを可視化する手法の一つです。
度数分布表
度数分布表は、データの区間をN等分して、その区間にどのようにデータが分布しているかを示した表になります。
それではirisのデータの中のsepal length(がく片の長さ)で度数分布表を作ってみます。
区間は10等分することとします。
sepal_lengths = pd.Series(df['sepal length (cm)'])
cut = pd.cut(sepal_lengths, 10).value_counts()
cut.sort_index()
上記を実行すると以下の様な結果となります。

改めて表にしてみると以下の様になります。
| 範囲 | 数 |
|---|---|
| (4.296, 4.66] | 9 |
| (4.66, 5.02] | 23 |
| (5.02, 5.38] | 14 |
| (5.38, 5.74] | 27 |
| (5.74, 6.1] | 22 |
| (6.1, 6.46] | 20 |
| (6.46, 6.82] | 18 |
| (6.82, 7.18] | 6 |
| (7.18, 7.54] | 5 |
| (7.54, 7.9] | 6 |
前述のデータの詳細と比べると、最小値の約4.3から最大値の7.9までを10等分していて、そこにそれぞれどの様な分布になっているかが示されています。(3.6の幅ずつに分けられている)
ヒストグラム
ヒストグラムは度数分布表をプロットしたものとなります。
pandasでは簡単にヒストグラムを生成できるため、以下のコードでヒストグラムを表示してみます。
df.hist(bins=10)
結果は以下のような感じです。
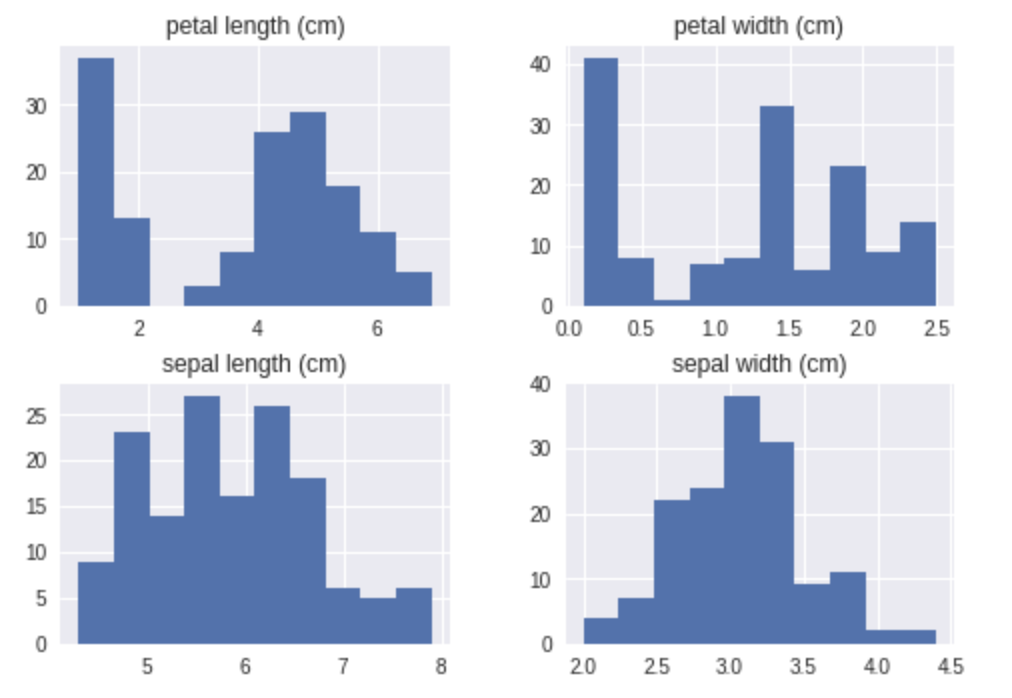
上記のヒストグラムは df.hist(bins=10)でデータを10個の区間に分けています。
前述の度数分布表と見比べても、だいたい同じ様になっているかと思います。
まとめ
- 度数分布表とヒストグラムはデータを可視化する基本的な手法
- pythonとその周辺ライブラリをつかえば、簡単実装できる
- ヒストグラムは探索的データ解析(EDA)の基礎中の基礎
参考
https://www.codexa.net/basic-exploratory-data-analysis-with-python/