こんにちは、 @kz_morita です。
日頃エンジニアの業務をしていると、ちょっとしたログファイルを解析したり、JSON ファイルの中身を検索したりなどそういったテキスト処理の作業が発生することがあります。
ちょっとした作業であれば VSCode などでファイルを開いて検索したり、置換したりすること解決できることが多いですがその際に正規表現を使うとかなり便利なことが多いです。
実際によくやる例
以下のような JSON ファイルがあるとします。
{
"project": {
"id": "12345",
"name": "Sample Project",
"description": "This project demonstrates JSON structure. More details are at https://example.com.",
"created_at": "2024-09-08T12:34:56Z",
"owner": {
"name": "John Doe",
"email": "john.doe@example.com",
"profile": "Visit John's blog at https://johndoe.example.com."
}
}
}
いくつか URL 文字列があるのでそれを抽出したいとします。 URLが専用のカラムにあれば、 jq などを使ってそのフィールドを抽出すれば良いですが上記みたいに文字列の中に埋め込まれている場合などには単純に抽出することが難しいです。
上記の例で example.com のドメインを検索するためには、以下のような正規表現を使うことができます。
(完全な正規表現ではないですが、簡単な例としてます)
^.*https://.*example\.com.*$
下記のように対象の列を取り出せます。
正規表現の例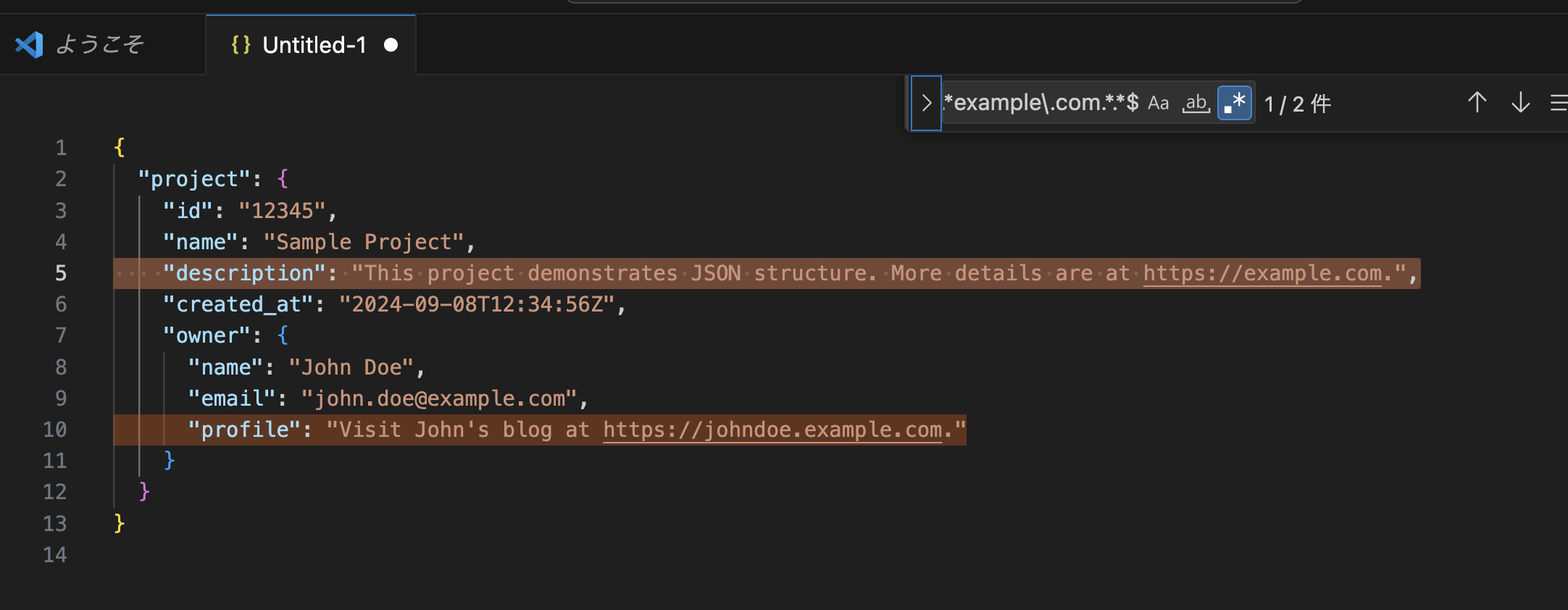
かりに、URLが含まれない行は削除してみたいとなったら以下のように否定系に正規表現を修正して置換すると実現できます。
^(?!.*https://.*example\.com.*).*$
否定系にすると example.com ドメイン以外の行のみをマッチできるので、これを削除するように置換できます。
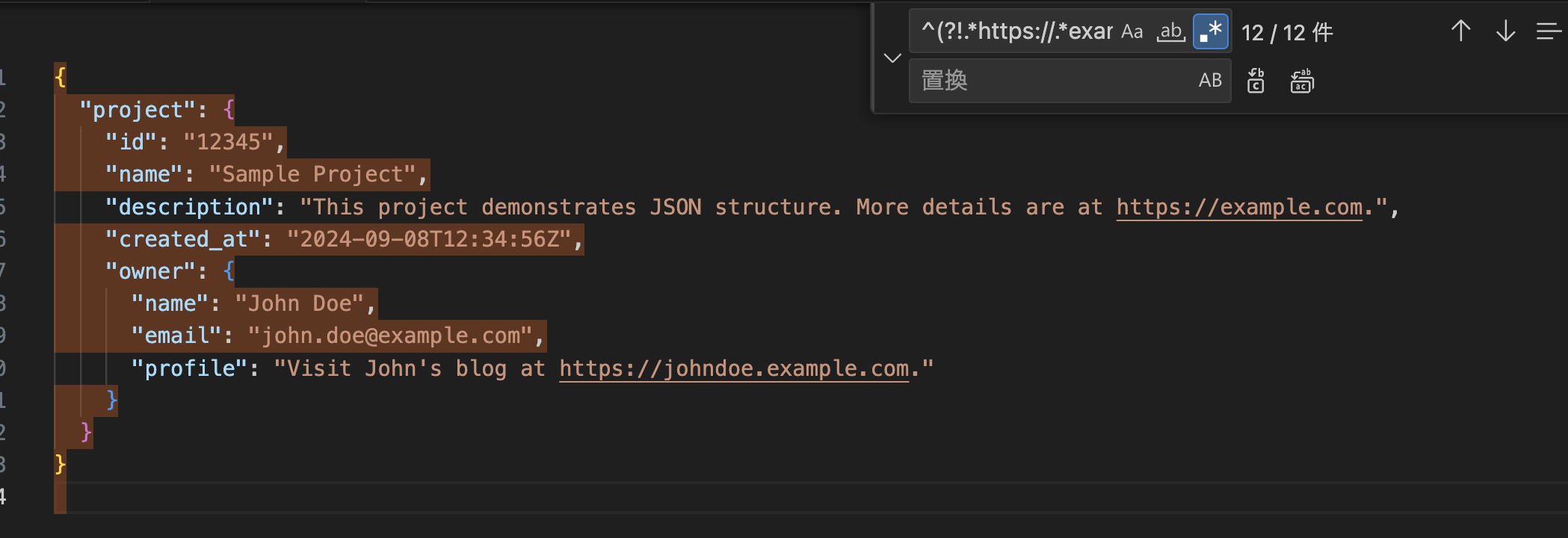
正規表現の置換例
あとは、example.com の URL が欲しければ、以下のような正規表現を使って抽出できます。
検索
^.*(https://.*example\.com).*$
置換
$1
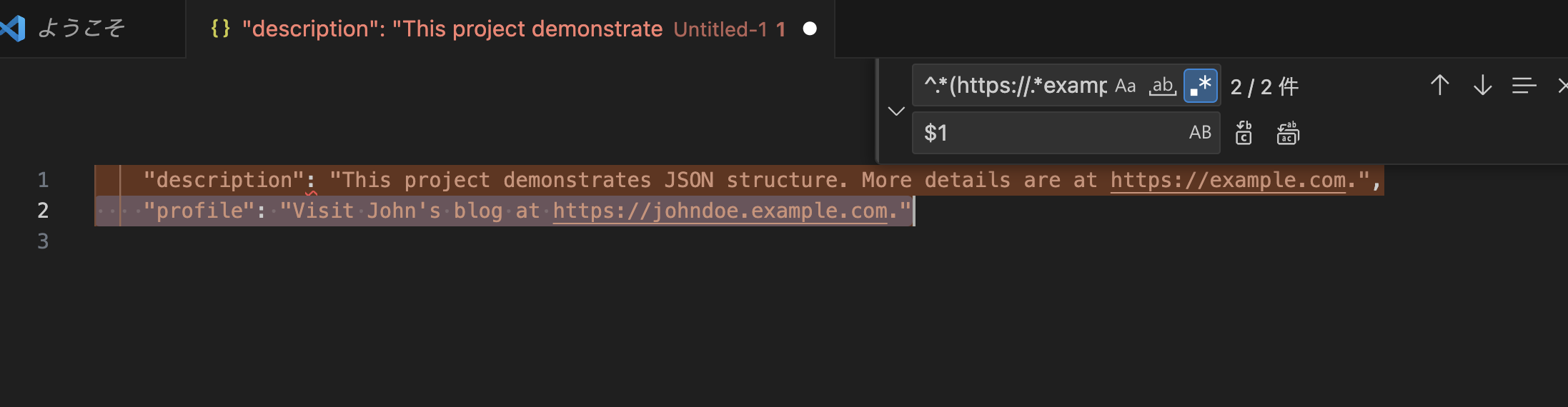
正規表現の抽出例
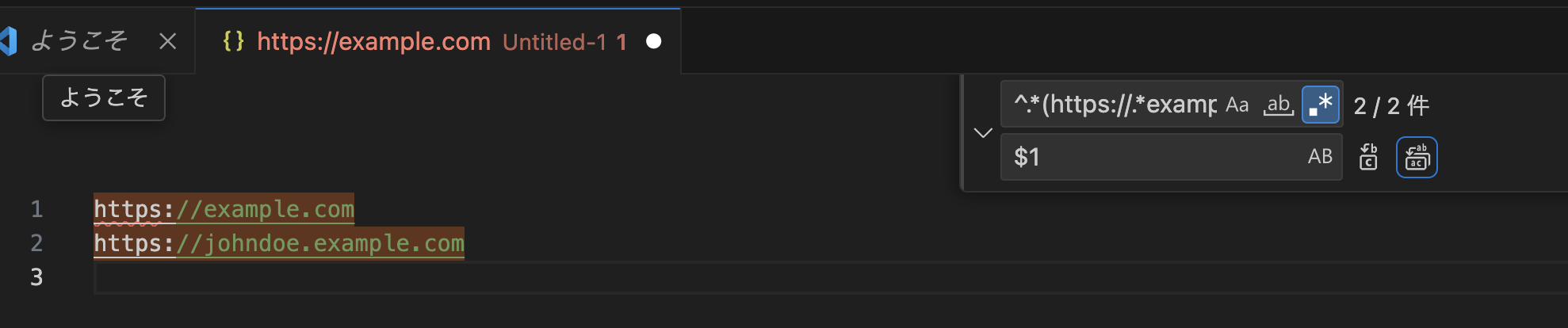
正規表現の抽出結果
これはわかりやすい例ですが、正規表現がわかると自分の目的の情報へのアクセスがかなり楽になることが多いです。 特にシステムとしてちゃんとつくるまえにさっくりと情報をみたいというタイミングにとても役立ちます。
まとめ
正規表現自体は古くからある技術ですが、テキスト処理においては今もよく使います。
最近だったら生成AI などに正規表現つくってもらったり、そもそも抽出自体をしてもらうみたいなこともできると思いますが一度正規表現学んでおくとかなり長い間役にたつ息の長いスキルなので学んでおいてよかったなと思いました。
ちなみに、自分は体系的に学びたかったため以下の書籍を読みました。目的通り体系的に学べるのでおすすめです。